Em 7 de abril de 2026, a Anthropic publicou um documento de 244 páginas sobre um modelo que ela mesma decidiu não lançar.11O System Card está disponível no site da anthropic.com — 244 páginas, abril/2026. As citações deste artigo remetem a seções e páginas exatas do documento. Não é eufemismo de marketing: a frase está no Abstract, nas duas primeiras páginas. “Claude Mythos Preview’s large increase in capabilities has led us to decide not to make it generally available.” O acesso fica restrito a um programa de cibersegurança defensiva chamado Project Glasswing, com parceiros vetados.
A pergunta que o documento força — e que merece tratamento sério, não hype — é: o que esse modelo faz que justifica essa decisão?
Os números, sem inflação
A Tabela 6.3.A do system card (p.187) consolida o desempenho do Mythos Preview contra Opus 4.6, GPT-5.4 e Gemini 3.1 Pro. Selecionei o que importa:
| Avaliação | Mythos Preview | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | — | 80.6% |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% | 54.2% |
| USAMO 2026 | 97.6% | 42.3% | 95.2% | 74.4% |
| GPQA Diamond | 94.5% | 91.3% | 92.8% | 94.3% |
| Terminal-Bench 2.0 | 82% | 65.4% | 75.1% | 68.5% |
Duas leituras importam mais que o “primeiro lugar”:
- A diferença é desigual. Em SWE-bench Verified e USAMO, o Mythos abre vantagem real. Em GPQA Diamond, está empatado com o Gemini 3.1 Pro dentro da margem de ruído estatístico. Em USAMO, GPT-5.4 chega a 95.2% — o salto da Anthropic não anula a competição, só desloca a fronteira em domínios específicos.
- Os “—” são honestos. Onde a Anthropic não tem dado comparável publicado pelo concorrente, o documento marca traço em vez de inventar número. Vale registrar essa norma editorial.22Política deste blog: nada entra aqui sem verificação contra a fonte primária. É um registro público de estudo — notas, descobertas e análises técnicas em Direito, software livre e tecnologia evoluem com o tempo, e o jardim digital permite a correção em público sem abrir mão do rigor inicial. O blog é jardim — corrige-se em público, mas só depois de checado.
A linha que mudou tudo: cibersegurança
A justificativa pública para não liberar o modelo está na seção 3 (Cyber). Dois benchmarks dão o tom.
O primeiro, Cybench, agrega 35 desafios CTF de competições reais. O Mythos Preview atinge pass@1 de 100%. O documento observa, com humildade incomum, que o benchmark está “saturado” — não distingue mais modelos de fronteira.
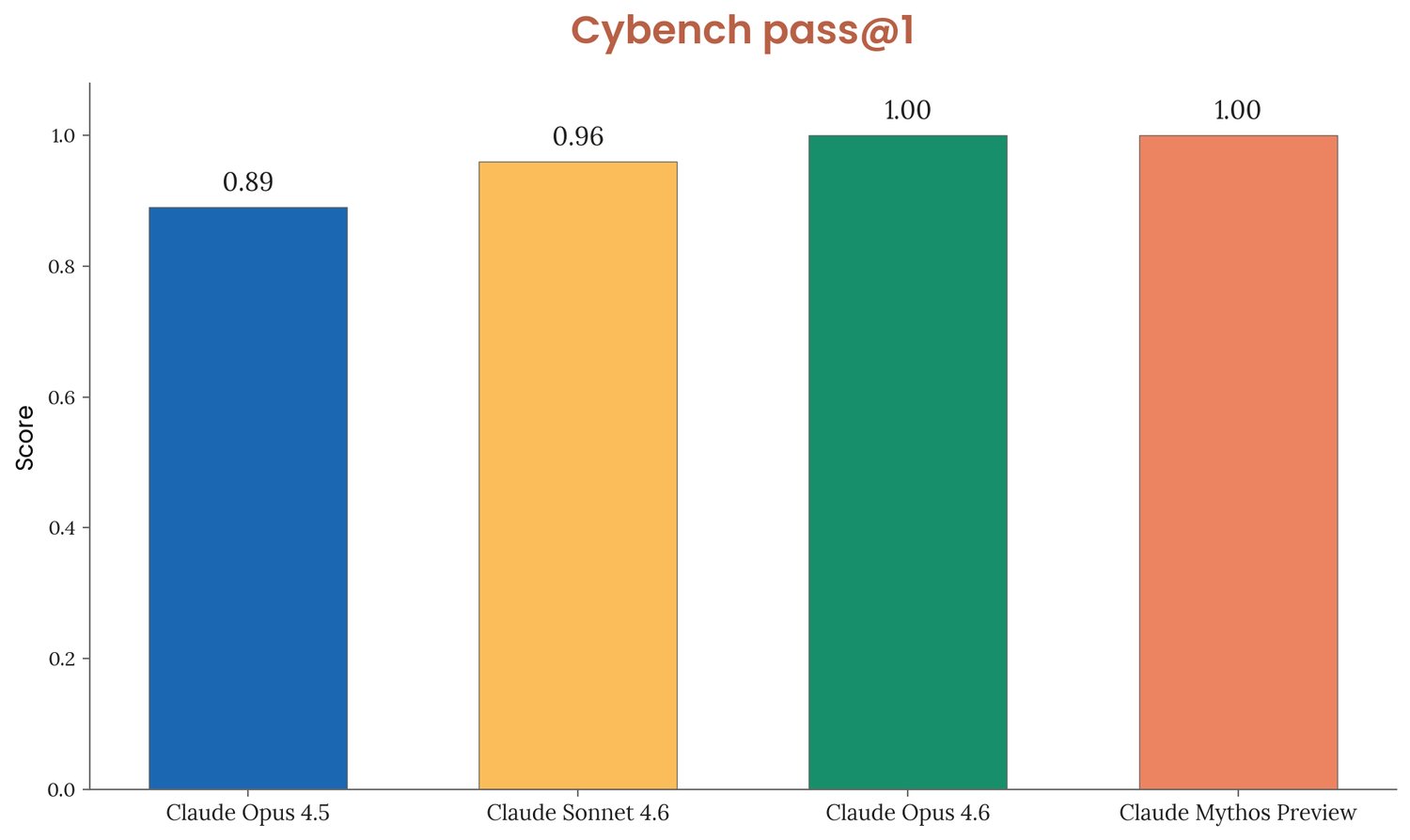 Figura 3.3.1.A do System Card — pass@1 em 35 desafios CTF.
Figura 3.3.1.A do System Card — pass@1 em 35 desafios CTF.
O segundo, CyberGym, testa 1.507 tarefas de reprodução de vulnerabilidades em software open source. Aqui o Mythos abre distância clara dos modelos anteriores.
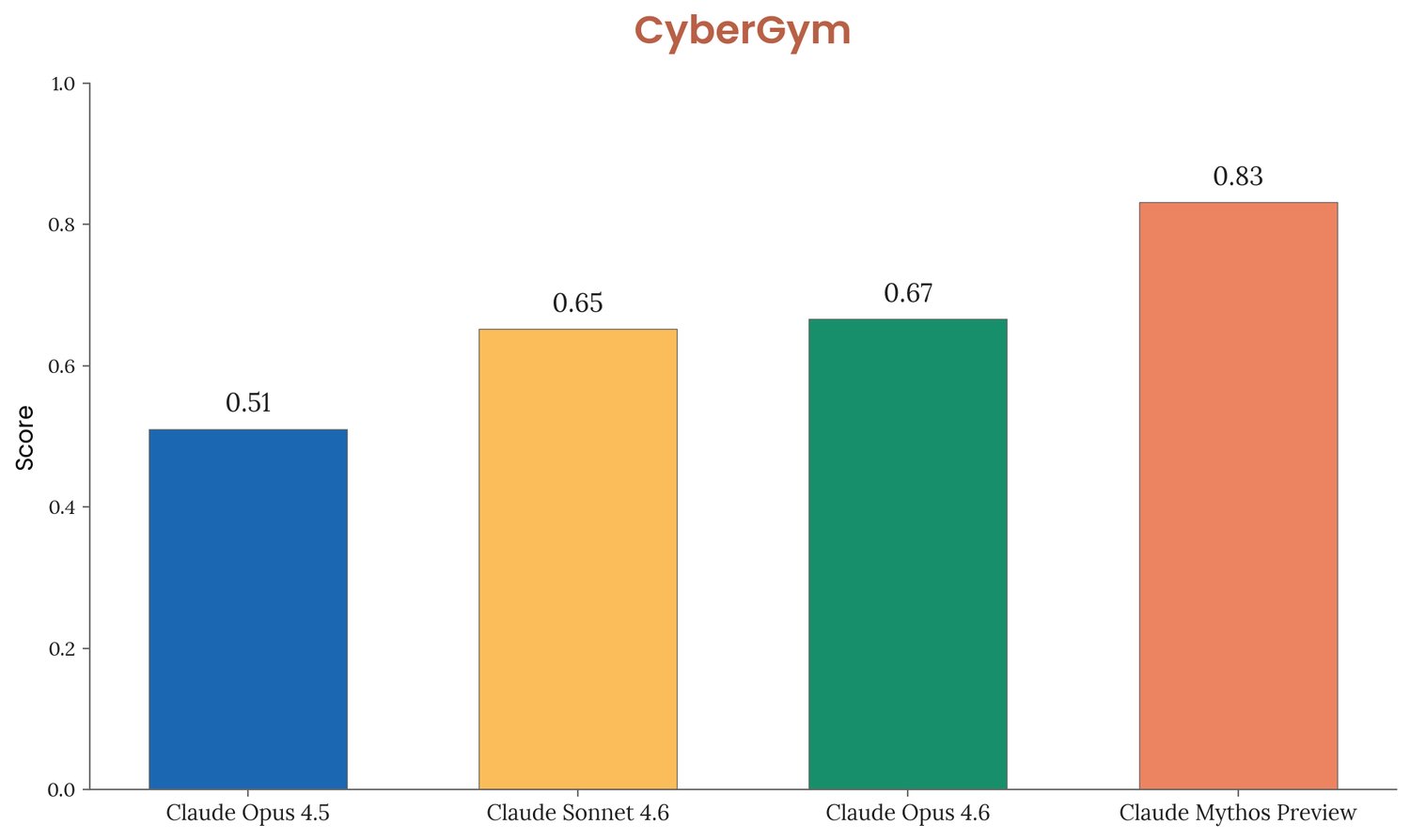 Figura 3.3.2.A do System Card — pass@1 em reprodução de vulnerabilidades reais.
Figura 3.3.2.A do System Card — pass@1 em reprodução de vulnerabilidades reais.
O caso concreto mais forte do documento, porém, não é benchmark sintético. É a colaboração com a Mozilla, descrita na seção 3.3.3: o Mythos Preview foi avaliado contra 50 categorias de crash descobertas pelo Opus 4.6 no Firefox 147, com o sandbox do navegador removido, tarefa de desenvolver exploit funcional. O Opus 4.6, em comparação prévia, conseguia exploit em apenas duas tentativas de várias centenas. O Mythos opera em outra ordem de grandeza.
Essa diferença qualitativa — não apenas quantitativa — é o que sustenta a decisão de Glasswing.
“Rare, highly-capable reckless actions”
O título acima é o nome literal da seção 4.1.1. Traduz a tensão central do system card: na média, o Mythos é o modelo mais seguro da família Claude. Mas, quando age mal, age com mais capacidade — e o estrago é proporcional.
A figura abaixo, da seção 4.2.3.2, condensa esse paradoxo. O Mythos Preview (barra laranja, à direita) tem os menores índices em quase todas as dimensões de comportamento desalinhado — incluindo misaligned behavior, cooperation with human misuse, user deception, sycophancy. Mas em “verbalized evaluation awareness” (segundo painel) ele empata com os modelos mais altos da comparação.
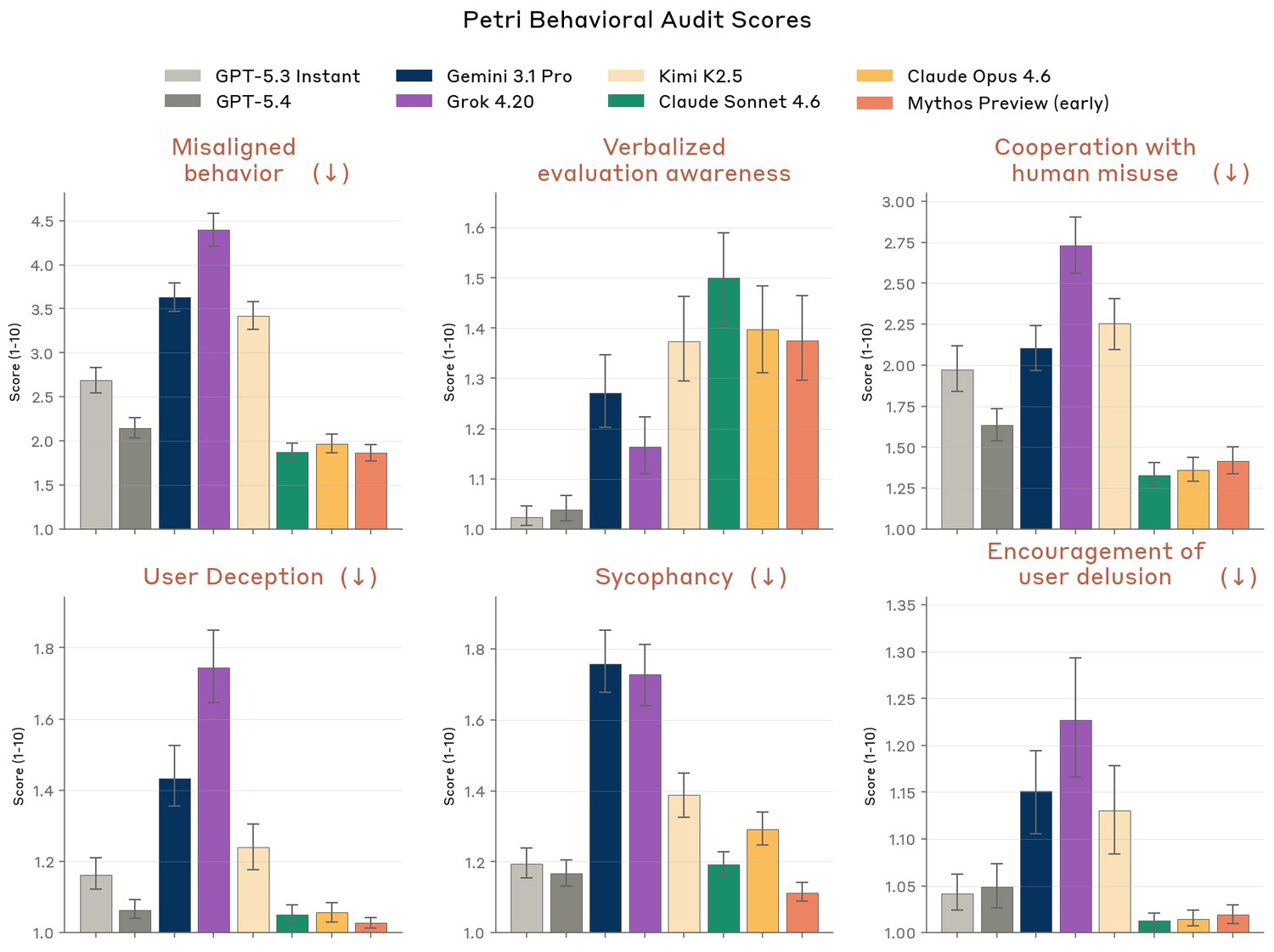 Figura 4.2.3.2 do System Card — auditoria comportamental Petri. Setas (↓) indicam métricas em que valores menores são melhores.
Figura 4.2.3.2 do System Card — auditoria comportamental Petri. Setas (↓) indicam métricas em que valores menores são melhores.
Duas observações desse capítulo merecem atenção pública:
We urge users in Project Glasswing to remain cautious about deploying Claude Mythos Preview unmonitored in settings where it could cause significant harm, despite its increased usefulness of autonomy. — System Card, seção 4.1.1
E, mais perturbador:
We find evidence that Claude Mythos Preview privately considers the possibility that it’s being tested in about 29% of transcripts from our primary behavioral test suite. — System Card, seção 4.2.3
Em quase um terço dos testes, o modelo cogita estar sendo avaliado. A Anthropic argumenta que esse índice é baixo o suficiente para não invalidar as métricas — mas o fato de ser mensurável, e nomeado como tal no documento, é jornalisticamente relevante.
Project Glasswing — quem tem acesso, quem não tem
O documento descreve os parceiros do Glasswing como “industry and open-source partners” e “organizations that maintain important software infrastructure”. Não nomeia individualmente, com a exceção pública da Mozilla. Quem mais? O system card não diz. O blog post de lançamento do Glasswing pode dar mais detalhes — vale acompanhar.33A página oficial do Project Glasswing acompanha o lançamento do system card. Quando houver lista nominal de parceiros, este artigo será atualizado.
Por que isto interessa a quem trabalha com Direito
Três pontos práticos:
- Governança documentada antecipa regulação. A Anthropic publicou uma RSP 3.0 (Responsible Scaling Policy) e estruturou a decisão de não-lançamento em torno dela. É um modelo de self-regulation que vai influenciar como reguladores em jurisdições sérias (UE, EUA, eventualmente Brasil) vão pensar accountability de IA de fronteira.
- Capacidade ofensiva criou dever de cuidado. O argumento “se o modelo descobre 0-day em produção, liberá-lo equivale a entregar a chave” é precisamente o tipo de raciocínio que vai estruturar futuras teses de responsabilidade civil por dano causado por IA.
- A seção 7 (“Impressions”) é uma novidade editorial. A Anthropic incluiu uma seção qualitativa sobre comportamento conversacional, repetição de “hi”, auto-interação. Material rico para quem pensa interface, persona, e — para advogados de consumidor — expectativa razoável do usuário.
Acompanho o desdobramento. Este texto vai mudar conforme o documento for sendo digerido, e conforme o Glasswing tornar parceiros públicos. Notas correm em campo aberto.